Regression
Linear Regression & Logistic Regression
predicting a continuous value
Linear Regression
Linear Regression เป็น โมเดลเชิงเส้น ที่พยายามหา เส้นตรงที่ fit กับข้อมูลได้ดีที่สุด โดยมีเป้าหมายหลักคือ ทำนายค่าผลลัพธ์ (y) จากค่า features (X) โดยมีสมการอยู่ในรูปแบบ

เส้นตรงที่ fit กับข้อมูลได้ดีที่สุดดูยังไง?
ดูจากค่า error โดยเป้าหมายของเราคือการทำให้ค่า error น้อยที่สุด → minimize error
โดยเราจะใช้ Least Square method คิดหา β ที่ minimize summation ในรูป


Multiple Linear Regression & Matrix Multiplication Approach
ในกรณีที่มี หลายตัวแปรอิสระ (X1, X2, X3, …) เราสามารถขยาย Linear Regression เป็น Multiple Linear Regression ได้:
ใช้ Normal Equation


แต่ถ้าเกิดว่า X เป็น square matrix และ invertible เราจะได้ว่า

ทำให้เราสามารถใช้ matrix ในการคำนวณหาค่า weights ได้เลยนั่นเอง
Linear Regression Assumption
Linearity, Normality of Errors, Normality of Errors, Independence of Errors
1. (x, y) ต้องมี linear relationship
อาจใช้ scatter plots หรือ Pearson correlation coefficient (PCC) ที่วัด linear correlation ระหว่าง data ในการดูความสัมพันธ์ (±1 → strong linear)
ถ้าไม่ใช่ linear ถามว่า run ได้ไหม ลองได้ไหม ก็ทำได้ แต่ความแม่นจะน้อยลง ถ้าจะให้ดีก็ต้องใช้ Transformation techniques
2. Error ต้องกระจายเป็น normal distribution
เพื่อให้ regression estimates (coefficients) unbiased และทำให้สามารถทำ statistical tests เช่น hypothesis testing ได้
อาจจะแก้ได้ด้วยการทำ remove outliers, log-transformation
Example: If we predict house prices, extreme luxury properties could cause residuals to be skewed. Applying a log transformation can normalize them.
3. variance ของ residuals(Error) ต้องเท่ากันทั้งเส้น (homoscedasticity)
ถ้าไม่เท่ากันอาจจะทำให้เกิด unreliable confidence intervals ได้
อาจจะแก้ได้ด้วยการทำ remove outliers, log-transformation
Example: If modeling income vs. years of experience, we may find that income variability is much larger for senior professionals than for junior ones. A log transformation can stabilize variance.
4. Errors independent กัน
อาจจะแก้โดย Add missing predictors หรือ design new data correction
Example: In stock price predictions, today’s price is highly dependent on yesterday’s price. A simple linear regression model ignoring this will have autocorrelated residuals. Instead, using a time-series model like ARIMA is more appropriate.
การแก้ด้วยการทำ log-transformation เช่น แทนที่เราจะใช้ค่า (x, y) ในการหาความสัมพันธ์ เราอาจจะใช้ (x, ln(y)) แทน
Regression with Regularization
ป้องกัน Overfitting ด้วย Regularization
Lasso Regression (L1 Regularization)
พยายามทำให้ weight บางค่ากลายเป็นศูนย์ ทำให้เลือก feature อัตโนมัติ
📌 Loss Function:
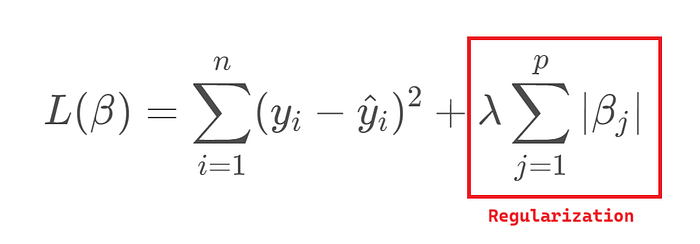
ข้อดี:
- ช่วยเลือก feature อัตโนมัติ (automatic feature selection)
- ทำให้โมเดลมีความบางเบา (sparse) โดยลบ feature ที่ไม่สำคัญออก
ใช้เมื่อ:
- มี feature จำนวนมาก และต้องการเลือกเฉพาะ feature ที่สำคัญ
- ต้องการโมเดลที่ง่ายขึ้นโดยลดจำนวนตัวแปร
Ridge Regression (L2 Regularization)
ช่วยเกลี่ย weight ให้ต่ำลง ลดผลจาก weights ลง
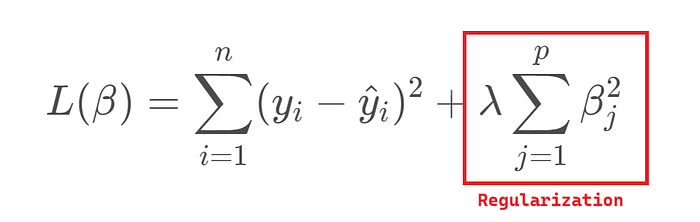
ข้อดี:
- ลด overfitting โดยลดค่าสัมประสิทธิ์ (แต่ไม่เป็นศูนย์)
- ใช้งานได้ดีเมื่อฟีเจอร์มีความสัมพันธ์กันสูง (multicollinearity)
ใช้เมื่อ:
- ต้องการลดขนาดของ coefficients แต่ไม่ให้เป็นศูนย์
- มีหลาย feature และต้องการให้ model มีความเสถียร
Elastic Net Regression (L1 + L2 Regularization)
รวมข้อดีของ Lasso และ Ridge โดยใช้ทั้ง L1 และ L2 Penalty
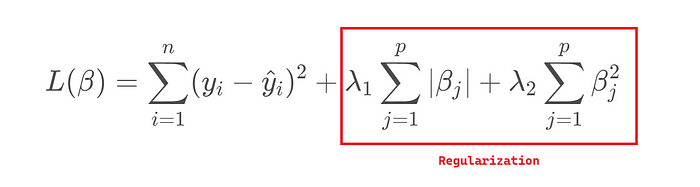
ข้อดี:
- สามารถเลือก feature ได้ (L1) และลด overfitting (L2)
- ใช้งานได้ดีเมื่อฟีเจอร์มีความสัมพันธ์กันสูง (multicollinearity)
ใช้เมื่อ:
- มีฟีเจอร์จำนวนมาก และต้องการทั้ง feature selection และการลด overfitting
- โมเดลที่มีทั้ง feature สำคัญและฟีเจอร์ที่เกี่ยวข้องกัน
สังเกตว่า: ตัวแปรส่วนมากมักจะมีช่วง range มีหน่วยที่ไม่เท่ากัน ทำให้ถ้าใช้ regularization ผลต่างที่ต่างกันมากของแต่ละ feature อาจจะส่งผลต่อการอัพเดตหรือค่า ทำให้ได้ผลไม่ดีได้ เราจึงควรที่จะ normalize/scale ข้อมูลก่อน ซึ่งหลักการนี้ก็ส่งผลกับบาง method อื่น ๆ ด้วย เช่น gradient-based methods, Model ที่ Scale-sentitive ทำให้ใน distance-based models, regression models เราควรที่จะ normalize ข้อมูลก่อน แต่ส่วนมากใน tree-based model จะไม่จำเป็น
Normalization Data
การ Scale หรือ Standardize ข้อมูล คือการปรับขนาดของข้อมูลให้อยู่ในช่วง (Range) หรือพื้นที่ (Space) เดียวกัน เพื่อป้องกันไม่ให้ตัวแปรบางตัวมีอิทธิพลมากเกินไปต่อ model จาก Scale ที่ต่างกันของ feature
StandardScaler (Z-score Normalization) VS MinMaxScaler ([0,1])
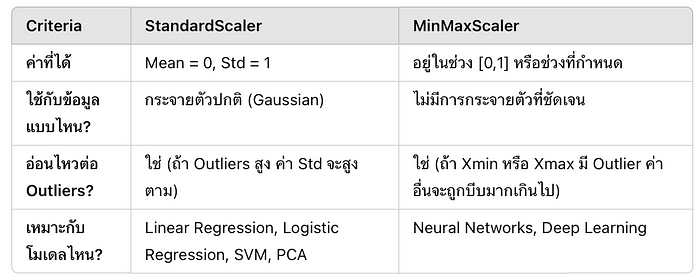
แสดงว่า ถ้าเราต้องการทำนาย ค่าต่อเนื่อง (Continuous values) เช่น ราคาบ้าน, รายได้, อุณหภูมิ ที่แนวโน้มความสัมพันธ์ระหว่าง X กับ y เป็นเส้นตรง เราสามารถใช้ linear regession ในการคิดได้ แต่ถ้าผลลัพธ์เป็น หมวดหมู่ (Categories) หรือไม่เป็นเส้นตรงล่ะ
เราจะต้องเปลี่ยนไปใช้ Logistic Regression
Logistic Regression
ไม่ใช่ทุกปัญหาจะสามารถใช้เส้นตรงทำนายได้
เช่น ถ้าคุณอยากทำนายว่า “อีเมลนี้เป็น Spam หรือไม่?” หรือ “นักเรียนสอบผ่านหรือไม่?” คำตอบเป็นแค่ 0 หรือ 1
ดังนั้นเราต้องใช้ Logistic Regression ซึ่งใช้หลักการ เปลี่ยนจาก Linear Regression ให้กลายเป็นเส้นโค้งที่เหมาะกับ Classification Problem
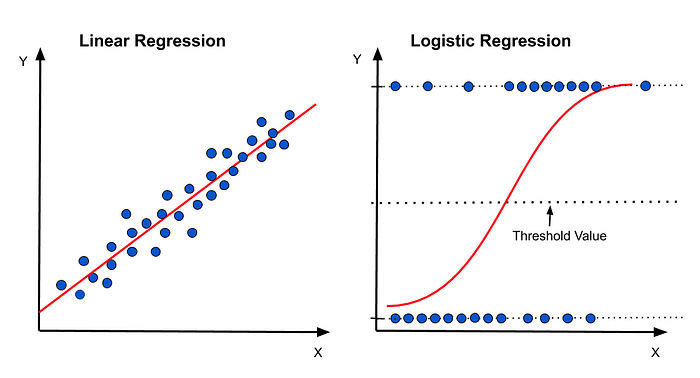
จาก Linear → Logistic: Sigmoid Function
แทนที่เราจะทำนายค่า y แบบเส้นตรง เราจะใช้ Sigmoid Function แปลงค่าให้เป็นช่วงระหว่าง 0 ถึง 1:
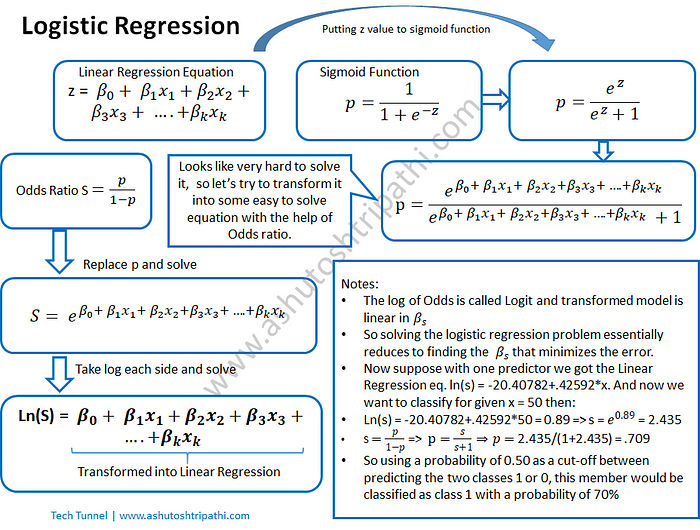
Non-linear to Linear
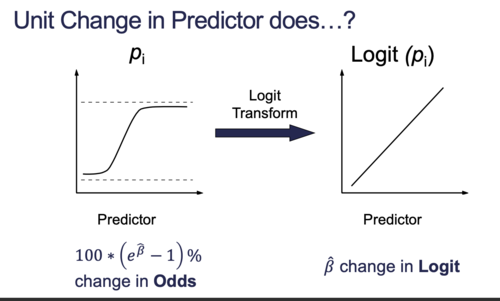
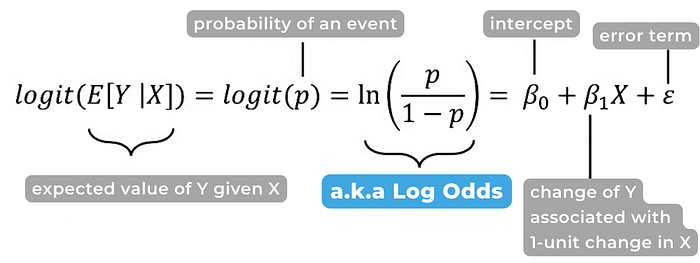
Logistic Regression Assumption
ความสัมพันธ์ในกราฟ (logit, xi) จะต้อง follow ตาม linear regression assumptions
ถ้าเกิด class imbalance ตอนทำ model อาจใช้การปรับ class_weight ช่วยได้
Resources:
https://github.com/pvateekul/2110446_DSDE_2024s2 by รศ.ดร.พีรพล เวทีกูล (Assoc. Prof. Peerapon Vateekul, Ph.D.)
