Model Evaluation
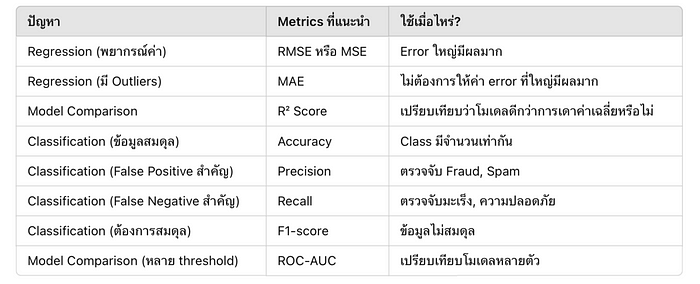
Evaluation metrics for Regression and Classification problem
เมื่อเราสร้างโมเดล Machine Learning แล้ว เราจำเป็นต้อง วัดผลลัพธ์ของโมเดล เพื่อดูว่ามันทำงานได้ดีแค่ไหน ซึ่งเราสามารถใช้วิธีการวัดที่แตกต่างกันไปขึ้นอยู่กับประเภทของปัญหา เช่น Regression (การพยากรณ์ค่า) และ Classification (การจัดหมวดหมู่)
Model Evaluation สำหรับ Regression
Regression คือปัญหาที่ต้องพยากรณ์ค่าต่อเนื่อง (Continuous Variable) เช่น คาดการณ์ราคาบ้าน, พยากรณ์อุณหภูมิ ฯลฯ
1. Sum of Squared Errors (SSE)

- วัดผลรวมของค่าความผิดพลาดที่ยกกำลังสอง
- ค่ายิ่งต่ำยิ่งดี เพราะหมายถึงโมเดลทำนายค่าใกล้เคียงความจริงมากขึ้น
- ใช้ได้ดีในกรณีที่ต้องการให้โมเดลโฟกัสกับจุดที่มีความผิดพลาดสูง
2. Average Squared Error (ASE) / Mean Squared Error (MSE)

- หาค่าเฉลี่ยของ SSE เพื่อให้ค่า Error มีมาตรฐานเดียวกัน
- ยิ่งค่า MSE น้อย โมเดลยิ่งแม่นยำ
- ข้อเสียคือ ใช้หน่วยเป็น ยกกำลังสองของหน่วยต้นฉบับ เช่น ถ้าพยากรณ์ราคาบ้านเป็นล้านบาท MSE จะเป็น ล้านบาท² ซึ่งอาจเข้าใจยาก
3. Root Mean Squared Error (RMSE)

- เป็น รากที่สองของ MSE ทำให้หน่วยกลับมาเป็นหน่วยเดียวกับค่าจริง
- ค่าน้อยหมายถึงโมเดลมี Error น้อย
- เหมาะกับโมเดลที่ต้องการให้ความผิดพลาดในหน่วยที่เข้าใจง่าย เช่น พยากรณ์ราคาบ้าน RMSE จะอยู่ในหน่วย “บาท”
4. Mean Absolute Error (MAE)

คำนวณจากค่า Error แบบ ค่าสัมบูรณ์ (absolute)
- ให้ค่า error ที่สามารถแปลความหมายได้ง่าย เช่น ค่าเฉลี่ยของ Error อยู่ที่ 5,000 บาท
- ไม่อ่อนไหวต่อ Outlier เท่า RMSE เพราะไม่มีการยกกำลังสอง
5. Coefficient of Determination (R² Score)

- วัดว่าโมเดลอธิบายความแปรปรวนของข้อมูลได้ดีแค่ไหน
- ค่า R² อยู่ระหว่าง 0 ถึง 1
- 1 → โมเดลทำนายค่าได้ตรง 100%
- 0 → โมเดลใช้ไม่ได้เลย
- ใช้เปรียบเทียบประสิทธิภาพของโมเดลที่ต่างกัน
- ถ้าค่า R² สูงเกินไป (ใกล้ 1 มากเกินไป) อาจ Overfitting
SSE, SSM, SST และ R2
ใน Regression Analysis เราจะใช้แนวคิดของความแปรปรวนรวม (Total Variation) และแบ่งออกเป็น 3 ส่วนหลัก คือ
- Sum of Squares Total (SST)
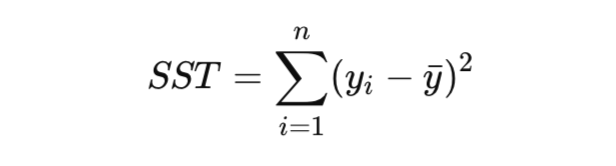
- เป็นค่าความแปรปรวนทั้งหมดของข้อมูลจริง ก่อนใช้โมเดล
- ใช้เปรียบเทียบว่าโมเดลของเราทำให้ค่าความผิดพลาดลดลงจากค่าเฉลี่ยเดิมได้มากแค่ไหน
2. Sum of Squares Regression (SSM หรือ SSR, Sum of Squares Model)
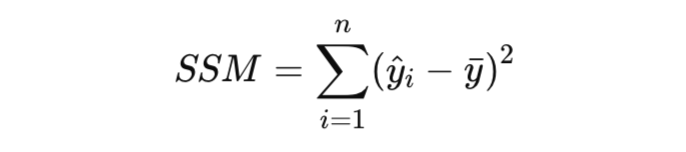
โมเดลช่วยอธิบายข้อมูลได้ดีแค่ไหน
- วัดความแปรปรวนของค่าที่โมเดลพยากรณ์เมื่อเทียบกับค่าเฉลี่ยของข้อมูล
- ค่ายิ่งสูง แสดงว่าโมเดลสามารถจับแนวโน้มของข้อมูลได้ดี
3. Sum of Squares Error (SSE หรือ Residual Sum of Squares, RSS)
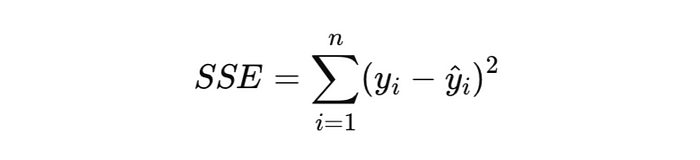
Model พยากรณ์ผิดพลาดมากแค่ไหน
- วัดความผิดพลาดของโมเดล (Residual หรือ Error)
- ค่ายิ่งต่ำ หมายความว่าโมเดลสามารถพยากรณ์ค่าใกล้เคียงความจริงได้มากขึ้น
สูตรการคำนวณ R2 เขียนได้อีกแบบว่า
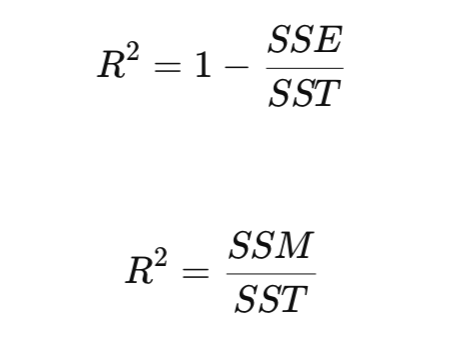

หากเราไม่มีโมเดลเลย สิ่งที่เราทำได้ดีที่สุดคือ ใช้ค่าเฉลี่ยของข้อมูลเป็นค่าพยากรณ์ ซึ่งหมายความว่า

ถ้า R2 ต่ำและ SSE สูง อาจต้องปรับปรุงฟีเจอร์
Model Evaluation สำหรับ Classification
Classification คือปัญหาที่ต้องจัดหมวดหมู่ เช่น Spam Detection (อีเมลเป็นสแปมหรือไม่), Credit Scoring (ลูกค้าจะจ่ายหนี้ไหม)
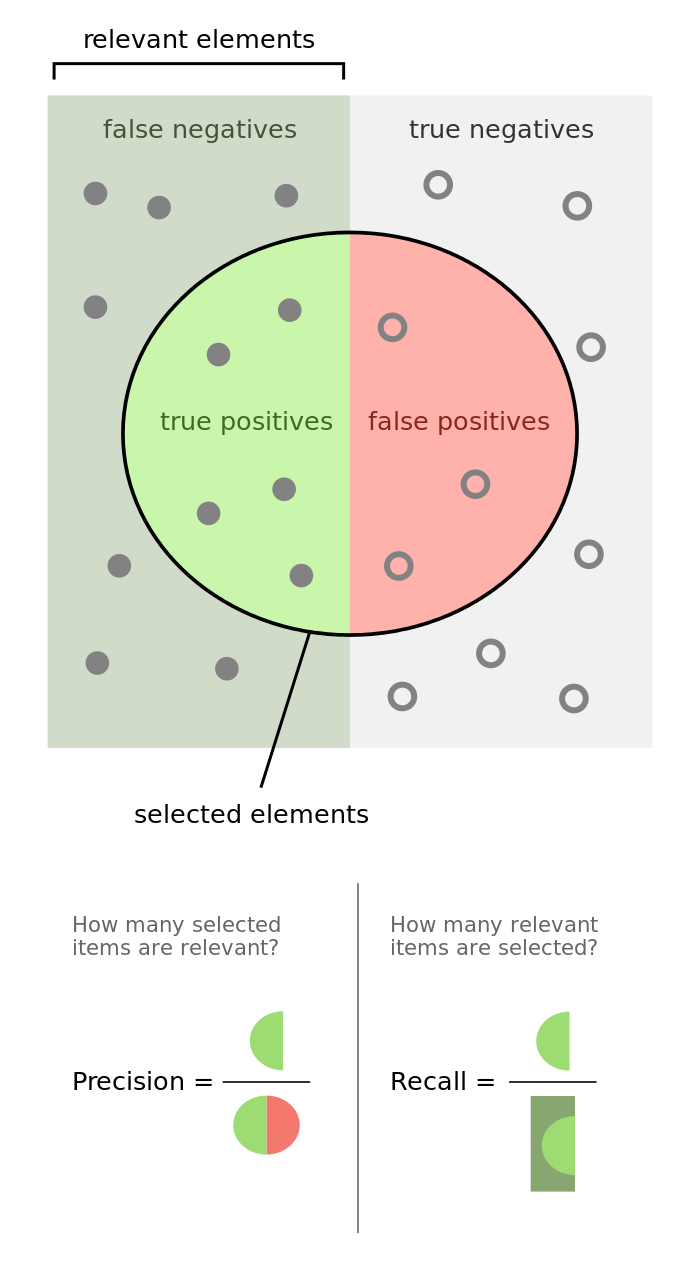
1. Confusion Matrix
Confusion Matrix ใช้สำหรับวิเคราะห์ผลลัพธ์ของโมเดล โดยแบ่งเป็น
- True Positive (TP) → ทำนายถูกว่าเป็นจริง
- True Negative (TN) → ทำนายถูกว่าปลอม
- False Positive (FP) → ทำนายผิดว่าเป็นจริง
- False Negative (FN) → ทำนายผิดว่าปลอม
True/False → เราทำนาย ถูก/ผิด
Positive/Negative → สิ่งที่เราทำนาย จริง/ไม่จริง

2. Accuracy

- เป็น สัดส่วนของผลลัพธ์ที่ถูกต้อง จากทั้งหมด
- ใช้ได้ดีเมื่อข้อมูลมีการกระจายที่สมดุลกัน
- ไม่เหมาะกับปัญหาที่ข้อมูลไม่สมดุล เช่น Fraud Detection (90% ปกติ 10% โกง)
3. Precision (ความแม่นยำ)

- วัดว่า จากสิ่งที่โมเดลทำนายว่าเป็นบวก มีเท่าไหร่ที่ถูกต้องจริง
- ใช้ในกรณีที่ False Positive มีผลกระทบสูง เช่น การตรวจโรคร้ายแรง
4. Recall (Sensitivity, True Positive Rate)

- วัดว่า จากทั้งหมดที่ควรเป็นบวก โมเดลทำนายถูกต้องแค่ไหน
- ใช้ในกรณีที่ False Negative มีผลกระทบสูง เช่น ตรวจโรคมะเร็ง ถ้า FN สูง = คนไข้ที่เป็นโรคถูกมองข้าม
5. F1-Score

- เป็นค่าเฉลี่ยเชิงกลมกลืน (Harmonic Mean) ระหว่าง Precision และ Recall
- เหมาะกับปัญหาที่ข้อมูลไม่สมดุล
- ค่า F1 ใกล้ 1 แปลว่าโมเดลดี
6. ROC Curve & AUC (c-statistic)

- ROC Curve (Receiver Operating Characteristic Curve) คือกราฟที่วัด True Positive Rate (Recall) เทียบกับ False Positive Rate (FPR)
- AUC (Area Under the Curve) วัดพื้นที่ใต้ ROC Curve
- AUC ใกล้ 1 = โมเดลแยกข้อมูลได้ดีมาก
- AUC ใกล้ 0.5 = โมเดลแย่ พอ ๆ กับการเดาสุ่ม
7. Lift Chart & Gain Chart
- Lift Chart → เปรียบเทียบว่าโมเดลสามารถแยกกลุ่มได้ดีแค่ไหนเทียบกับการสุ่ม
- Gain Chart → วัดว่าถ้าเลือก N% ของข้อมูล เราจะจับกลุ่มเป้าหมายได้กี่เปอร์เซ็นต์
Summary
Regression Metrics
การวัดความแม่นยำของโมเดลที่ใช้พยากรณ์ค่าเชิงตัวเลข เช่น การทำนายราคาบ้าน หรืออุณหภูมิ
- Mean Squared Error (MSE): วัดค่าความผิดพลาดเฉลี่ยของโมเดล โดยให้ความสำคัญกับ error ใหญ่ ๆ (error ถูกยกกำลังสอง)
- Root Mean Squared Error (RMSE): เป็น MSE ที่ถูกถอดรูท เพื่อให้ค่ากลับมาอยู่ในหน่วยเดียวกับค่า y จริง
- Mean Absolute Error (MAE): คล้าย MSE แต่ใช้ค่าสัมบูรณ์ แปลว่า error ขนาดใหญ่จะไม่ถูกขยายมากเหมือน MSE
- R² Score (Coefficient of Determination): คำนวณว่าสัดส่วนของความแปรปรวนในข้อมูลสามารถอธิบายโดยโมเดลได้มากแค่ไหน วัดว่าโมเดลดีขึ้นแค่ไหนเมื่อเทียบกับ baseline
- Sum Squared Error (SSE): เป็นผลรวมของ error ทั้งหมดแบบยกกำลังสอง ยิ่งน้อยยิ่งดี
- Total Sum of Squares (SST): เป็นการวัดว่าค่าจริงกระจายจากค่าเฉลี่ยของข้อมูลมากแค่ไหน
Guidelines
- ถ้าต้องการให้ความสำคัญกับ error ใหญ่ ๆ → ใช้ RMSE หรือ MSE
- ถ้ามี outliers มาก → MAE อาจจะดีกว่า MSE เพราะ error ขนาดใหญ่มีผลน้อยกว่า
- ถ้าต้องการเปรียบเทียบโมเดล → ใช้ R² Score เพื่อดูว่าโมเดลดีขึ้นกว่าการเดาค่าเฉลี่ยหรือไม่
Classification Metrics
ใช้วัดความสามารถของโมเดลที่จำแนกข้อมูลออกเป็นกลุ่ม เช่น การคาดเดาว่าลูกค้าจะซื้อสินค้าหรือไม่
- Accuracy: วัดสัดส่วนของการทำนายที่ถูกต้องจากทั้งหมด
- Precision: วัดว่าจากทั้งหมดที่โมเดลทำนายว่าเป็น Positive มีเท่าไหร่ที่ถูกต้อง
- Recall (Sensitivity, True Positive Rate): วัดว่าโมเดลสามารถจับ Positive จริง ๆ ได้ดีแค่ไหน
- F1-score: เป็นค่าเฉลี่ยถ่วงน้ำหนักของ Precision และ Recall เหมาะสำหรับข้อมูลที่ไม่สมดุล
- Specificity (True Negative Rate): วัดว่าโมเดลสามารถระบุ Negative ได้ดีแค่ไหน
- False Positive Rate (FPR): วัดว่าโมเดลทำนายผิดพลาดโดยระบุว่าเป็น Positive ทั้งที่จริง ๆ เป็น Negative
- ROC Curve: กราฟแสดงความสัมพันธ์ระหว่าง TPR และ FPR ใช้เปรียบเทียบโมเดลที่มี threshold ต่างกัน
- Area Under ROC (AUC): ค่าพื้นที่ใต้เส้น ROC ถ้ายิ่งเข้าใกล้ 1 หมายถึงโมเดลแยกแยะ Positive กับ Negative ได้ดี
Guidelines
- ถ้าค่า False Positive สำคัญมาก → ใช้ Precision (เช่น ตรวจจับ Spam หรือ Fraud)
- ถ้าค่า False Negative สำคัญมาก → ใช้ Recall (เช่น การตรวจหาโรคร้ายแรง)
- ถ้าข้อมูลไม่สมดุล → ใช้ F1-score แทน Accuracy
- ถ้าเปรียบเทียบโมเดลหลายตัว → ใช้ ROC-AUC เพื่อดูว่าโมเดลไหนให้ผลดีที่สุด
Example